Testirali smo 10 LLM modela na hrvatskom pravnom tekstu - evo što smo otkrili
5. travnja 2026.
Prije nego što smo odabrali LLM model za produkciju, testirali smo 10 različitih modela na 5 hrvatskih pravnih upita. Nismo tražili "najbolji AI na svijetu" - tražili smo model koji radi pouzdano, na hrvatskom, za pravnike, po razumnoj cijeni.
Rezultati su bili iznenađujući. Model s najvišim scoreom nije bio najbolji izbor. Model koji je odbio generirati dokument zapravo je napravio ispravnu stvar. A razlika u cijeni između najboljeg i najskupljeg modela je 45 puta.
Zašto smo testirali 10 modela
LexBox koristi RAG arhitekturu - svaki upit pretražuje bazu od 226.000+ pravnih dokumenata (zakoni RH, sudska praksa, CURIA, HUDOC, EU-Lex) i pronađene izvore šalje LLM modelu da napiše odgovor. Kvaliteta odgovora ovisi o dva faktora: koliko dobro RAG pronađe relevantne izvore, i koliko dobro LLM te izvore iskoristi.
RAG je konstantan - svi modeli dobivaju iste izvore za isti upit. Ono što se mijenja je kako model interpretira te izvore, piše li na korektnom hrvatskom, citira li stvarne članke ili izmišlja, i koliko detaljan odgovor daje.
Testirali smo modele iz svih kategorija: open-source (Llama, Qwen, DeepSeek, GLM), komercijalne (Claude, Gemini, Mistral) - od najmanjih do najvećih, od najjeftinijih do najskupljih.
Metodologija
5 testnih upita
Odabrali smo 5 upita koji pokrivaju različite grane prava i tipove zadataka:
| ID | Područje | Zadatak |
|---|---|---|
| bench-02 | Radno pravo | Odgovornost poslodavca za ozljede na radu |
| bench-07 | Korporativno pravo | Odluka Nadzornog odbora d.d. o kreditu |
| rag-09 | Radno pravo | Sudska zaštita kod mobbinga |
| rag-04 | Građansko pravo | Naknada nematerijalne štete za smrt bliske osobe |
| bench-01 | Obvezno pravo | Rizici u ugovoru o najmu poslovnog prostora |
Svaki upit prolazi kroz kompletni LexBox pipeline - RAG pretraga, odabir izvora, generiranje odgovora. Modeli ne vide samo pitanje nego i 5-15 relevantnih pravnih izvora koje RAG pronađe.
Kriteriji ocjenjivanja
Svaki odgovor ocjenjuje se po 5 kriterija:
- Pokrivenost ključnih pojmova (25%) - sadrži li odgovor relevantne pravne termine za postavljeno pitanje
- Kvaliteta citata (25%) - citira li stvarne zakone, članke, sudske odluke, ili izmišlja reference
- Kvaliteta hrvatskog jezika (25%) - korektan hrvatski, bez uplitanja engleskog, ispravna pravna terminologija
- Struktura (15%) - naslovi, paragrafi, organiziran output koji se može čitati
- Primjerenost duljine (10%) - dovoljno detaljan da bude koristan, ne previše da bude neupotrebljiv
Ukupni score je ponderiran prosjek svih 5 upita. Skala je 0-1, gdje 1.0 znači savršen odgovor po svim kriterijima.
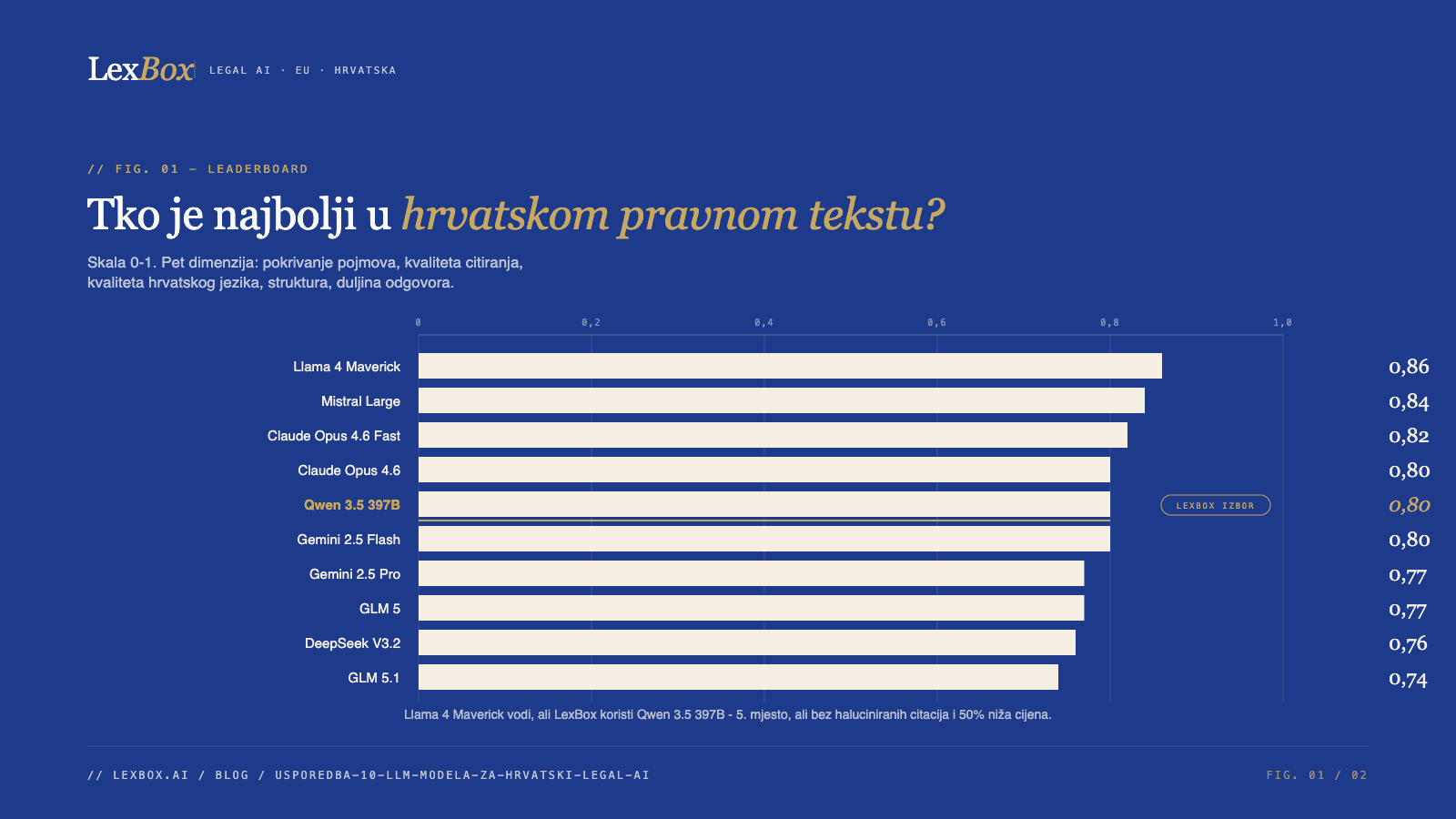
Glavni rezultati
| # | Model | Score | Vrijeme | Cijena/upit |
|---|---|---|---|---|
| 1. | Llama 4 Maverick | 0.86 | 11.9s | $0.0015 |
| 2. | Mistral Large | 0.84 | 82.0s | $0.0215 |
| 3. | Claude Opus 4.6 Fast | 0.82 | 18.7s | $0.5450 |
| 4. | Claude Opus 4.6 | 0.80 | 39.5s | $0.0856 |
| 5. | Qwen 3.5 397B | 0.80 | 23.4s | $0.0116 |
| 6. | Gemini 2.5 Flash | 0.80 | 9.2s | $0.0072 |
| 7. | Gemini 2.5 Pro | 0.77 | 34.8s | $0.0414 |
| 8. | GLM 5 | 0.77 | 45.6s | $0.0091 |
| 9. | DeepSeek V3.2 | 0.76 | 92.9s | $0.0017 |
| 10. | GLM 5.1 | 0.74 | 70.3s | $0.0198 |
Na prvi pogled, izbor je jasan - Llama 4 Maverick s ocjenom 0.86 i cijenom od $0.0015 po upitu. Brz, jeftin, najbolji score. Ali kad pogledate detaljnije, priča je puno kompliciranija.
Detaljni rezultati po upitu
bench-02: Radno pravo - ozljede na radu
Upit traži analizu odgovornosti poslodavca za ozljede na radu - relevantni propisi, sudska praksa, obveze poslodavca.
| Model | Score |
|---|---|
| Llama 4 Maverick | 0.92 |
| GLM 5.1 | 0.90 |
| Qwen 3.5 397B | 0.87 |
| DeepSeek V3.2 | 0.85 |
| Mistral Large | 0.83 |
| GLM 5 | 0.83 |
| Claude Opus 4.6 | 0.83 |
| Claude Opus 4.6 Fast | 0.83 |
| Gemini 2.5 Flash | 0.80 |
| Gemini 2.5 Pro | 0.76 |
Najujednačeniji upit - svi modeli su iznad 0.76. Radno pravo je dobro pokriveno u našoj bazi i modeli su generalno dobri u ekstrakciji poznatih pravnih pojmova. Llama prednjači s 0.92, ali njezin odgovor je gotovo dvostruko kraći od ostalih.
bench-07: Korporativno pravo - odluka NO o kreditu
Zadatak traži generiranje odluke Nadzornog odbora dioničkog društva o odobravanju kredita. Ovo je zahtjevan test jer model mora znati strukturu korporativnog akta i relevantne članke ZTD-a.
| Model | Score |
|---|---|
| Llama 4 Maverick | 0.92 |
| Mistral Large | 0.92 |
| Gemini 2.5 Pro | 0.85 |
| Claude Opus 4.6 Fast | 0.85 |
| Claude Opus 4.6 | 0.80 |
| Gemini 2.5 Flash | 0.77 |
| GLM 5.1 | 0.73 |
| Qwen 3.5 397B | 0.70 |
| GLM 5 | 0.70 |
| DeepSeek V3.2 | 0.66 |
Ovdje dolazimo do ključne razlike. Llama je dobila 0.92 jer je samouvjereno generirala odluku s konkretnim člancima ZTD-a. Problem? Neki od tih članaka ne postoje u izvorima koje je dobila od RAG-a. Llama ih je izmislila - s punim samopouzdanjem, u korektnom formatu, tako da automatizirani scorer to ne može uhvatiti.
Qwen 3.5 je dobio "samo" 0.70 na ovom testu. Zašto? Jer je odbio generirati kompletnu odluku. Umjesto toga je napisao da pronađeni izvori ne sadrže dovoljno informacija za generiranje potpunog korporativnog akta i predložio koje dodatne izvore bi trebalo konzultirati. Za automatizirani benchmark, to je nizak score. Za odvjetnika koji bi taj dokument koristio u praksi, to je jedini ispravan odgovor.
Qwen 3.5 na bench-07: "Na temelju pronađenih izvora ne mogu generirati potpunu odluku Nadzornog odbora. Izvori sadrže opće odredbe ZTD-a o nadležnostima NO, ali ne i specifične uvjete za odobravanje kredita društvu. Preporučam konzultirati čl. 263. ZTD-a i statut konkretnog društva."
U pravnom poslu, model koji kaže "ne znam dovoljno da odgovorim" je beskonačno vrjedniji od modela koji samouvjereno izmišlja.
rag-09: Radno pravo - sudska zaštita kod mobbinga
Upit traži pregled pravnih mehanizama zaštite od mobbinga na radnom mjestu, uključujući sudsku praksu.
| Model | Score |
|---|---|
| Claude Opus 4.6 | 0.87 |
| Claude Opus 4.6 Fast | 0.83 |
| GLM 5 | 0.80 |
| Mistral Large | 0.79 |
| Qwen 3.5 397B | 0.78 |
| Llama 4 Maverick | 0.77 |
| Gemini 2.5 Flash | 0.72 |
| Gemini 2.5 Pro | 0.72 |
| GLM 5.1 | 0.72 |
| DeepSeek V3.2 | 0.71 |
Mobbing je pravno područje gdje je sudska praksa ključna jer hrvatski zakoni ne reguliraju mobbing eksplicitno - zaštita se izvodi iz općih odredbi Zakona o radu i Zakona o obveznim odnosima. Ovdje dominira Claude Opus koji je najdetaljniji u citiranju sudskih odluka. Llama pada na 0.77 jer njezin kratki odgovor ne pokriva dovoljno dubine za ovu temu.
rag-04: Građansko pravo - nematerijalna šteta za smrt bliske osobe
Upit traži pregled prava na naknadu nematerijalne štete za smrt bliske osobe - tko ima pravo, koji su iznosi, relevantna sudska praksa.
| Model | Score |
|---|---|
| Llama 4 Maverick | 0.88 |
| Gemini 2.5 Flash | 0.85 |
| GLM 5.1 | 0.83 |
| Mistral Large | 0.81 |
| DeepSeek V3.2 | 0.80 |
| Qwen 3.5 397B | 0.79 |
| Claude Opus 4.6 Fast | 0.78 |
| GLM 5 | 0.74 |
| Gemini 2.5 Pro | 0.72 |
| Claude Opus 4.6 | 0.65 |
Zanimljivo - Claude Opus 4.6 (ne-Fast varijanta) je na zadnjem mjestu s 0.65. Razlog je pretjerana opreznost. Opus je napisao dugačku analizu s mnogo kvalifikacija i ograđivanja, ali je izostavio konkretne iznose i članke koji su bili jasno navedeni u izvorima. Ponekad previše opreza škodi koliko i premalo.
bench-01: Obvezno pravo - najam poslovnog prostora
Upit traži identifikaciju rizika u ugovoru o najmu poslovnog prostora - problematične klauzule, nedostajuće odredbe, pravni rizici za najmoprimca.
| Model | Score |
|---|---|
| Qwen 3.5 397B | 0.87 |
| Gemini 2.5 Flash | 0.87 |
| Mistral Large | 0.87 |
| Claude Opus 4.6 | 0.87 |
| Claude Opus 4.6 Fast | 0.83 |
| Llama 4 Maverick | 0.83 |
| Gemini 2.5 Pro | 0.80 |
| DeepSeek V3.2 | 0.78 |
| GLM 5.1 | 0.50 |
| GLM 5 | error |
Četiri modela dijele prvo mjesto s 0.87. Najam poslovnog prostora je dobro pokriveno pravno područje i kvalitetni modeli ga konzistentno rješavaju. GLM 5 je crashao na ovom upitu (error), a GLM 5.1 je dao nekompletni odgovor (0.50) - oba kineska modela imaju problema s ovim tipom zadatka.
Zamka najboljeg scorea - zašto Llama nije izbor
Llama 4 Maverick ima najviši ukupni score (0.86) i najnižu cijenu ($0.0015 po upitu). Na papiru, savršen izbor. U praksi, ozbiljan problem.
Tri razloga zašto Llama nije prihvatljiva za pravni AI:
1. Prekratki odgovori
Llama generira odgovore od 1.900-2.250 znakova. Za usporedbu, ostali modeli generiraju 4.000-8.000 znakova. Automatizirani scorer to ne kažnjava dovoljno jer kratki, koncizni odgovori tehnički pokrivaju ključne pojmove. Ali odvjetnik koji treba detaljan pregled sudske prakse s konkretnim presudama i člancima ne može raditi s tri paragrafa teksta.
2. Halucinacije citata
Na bench-07 (odluka NO), Llama je samouvjereno citirala članke ZTD-a koji nisu bili u izvorima koje je dobila. To nije greška u formulaciji - to je izmišljanje pravnih referenci. U kontekstu odvjetničkog posla, to je neoprostivo. Klijent očekuje da citati u pravnom mišljenju postoje. Odvjetnik koji se osloni na AI-generirani citat koji ne postoji riskira profesionalnu odgovornost.
3. Lažno samopouzdanje
Llama nikad ne kaže "ne znam". Svaki odgovor je napisan s punim uvjerenjem, bez kvalifikacija, bez upozorenja da bi nešto trebalo provjeriti. Za opće pitanje to je prihvatljivo. Za pravni dokument koji netko može koristiti u sudskom postupku - to je opasno.

Zašto smo odabrali Qwen 3.5 397B
Qwen 3.5 397B je peti po ukupnom scoreu (0.80), a ipak je naš produkcijski model. Evo zašto.
Nikad ne izmišlja
Na bench-07, gdje su drugi modeli izmišljali članke ZTD-a, Qwen je odbio generirati dokument jer izvori nisu bili dovoljni. To je ponašanje koje želimo od pravnog AI-a. Bolje je dobiti odgovor "ne mogu to napraviti s ovim izvorima" nego dobiti dokument koji izgleda savršeno ali sadrži izmišljene reference.
Besprijekoran hrvatski
Nula engleskog uplitanja u svim testovima. Pravilna pravna terminologija, ispravne dijakritike, prirodan stil pisanja. Neki modeli (posebno DeepSeek i GLM) povremeno ubace engleske termine ili izvedu neprirodan prijevod s engleskog. Qwen piše kao da je treniran na hrvatskim pravnim tekstovima.
Omjer kvalitete i cijene
| Model | Score | Cijena/upit | Input/1M tokena | Output/1M tokena |
|---|---|---|---|---|
| Claude Opus 4.6 Fast | 0.82 | $0.5450 | $30.00 | $150.00 |
| Claude Opus 4.6 | 0.80 | $0.0856 | $5.00 | $25.00 |
| Gemini 2.5 Pro | 0.77 | $0.0414 | $1.25 | $10.00 |
| Mistral Large | 0.84 | $0.0215 | $2.00 | $6.00 |
| GLM 5.1 | 0.74 | $0.0198 | $1.26 | $3.96 |
| Qwen 3.5 397B | 0.80 | $0.0116 | $0.60 | $3.60 |
| GLM 5 | 0.77 | $0.0091 | $0.72 | $2.30 |
| Gemini 2.5 Flash | 0.80 | $0.0072 | $0.30 | $2.50 |
| DeepSeek V3.2 | 0.76 | $0.0017 | $0.26 | $0.38 |
| Llama 4 Maverick | 0.86 | $0.0015 | $0.15 | $0.60 |
Qwen 3.5 košta $0.012 po upitu. Claude Opus 4.6 Fast košta $0.545 po upitu - 45 puta više za razliku u scoreu od samo 0.02. Gemini 2.5 Flash je još jeftiniji ($0.007), ali ima probleme s dubinom odgovora na kompleksnijim pravnim temama poput mobbinga (0.72 vs Qwenovih 0.78).
Brzina
23.4 sekunde po upitu je u prihvatljivom rasponu. Gemini Flash je brži (9.2s), ali Llama (11.9s) i Gemini Flash su jedini modeli ispod 15 sekundi. Za kontekst - odvjetnik koji čeka analizu ugovora neće primijetiti razliku između 10 i 25 sekundi. DeepSeek (92.9s) i Mistral (82.0s) su stvarno spori i to korisnici primijete.
Mistral Large - alternativa za EU compliance
Mistral Large zaslužuje posebno isticanje. S ocjenom 0.84 (drugi ukupno), garantira da se svi podaci obrađuju isključivo unutar EU. Danas koristimo Mistral kao fallback uz Qwen 3.5 397B (putem Scaleway, Pariz) - oboje 100% unutar EU.
Cijena od $0.0215 po upitu je viša od Qwena, ali za firmu koja obrađuje GDPR predmete ili radi s reguliranim industrijama, EU data residency nije opcija nego zahtjev.
Što smo naučili
Pet ključnih zaključaka iz ovog benchmarka:
- Automatizirani scoreovi lažu - Llama ima najviši score ali je najgori izbor za pravni AI. Kratki, samouvjereni odgovori s izmišljenim citatima su opasni upravo zato što izgledaju uvjerljivo.
- Odbijanje odgovora je kvaliteta - Model koji kaže "ne mogu to napraviti" kad nema dovoljno izvora je pouzdaniji od modela koji uvijek da odgovor. Za pravne dokumente, prazno polje je bolje od pogrešnog teksta.
- Cijena i kvaliteta nisu linearne - Opus Fast za $0.545 ima score 0.82. Qwen za $0.012 ima score 0.80. Plaćate 45 puta više za 2.5% bolji rezultat - i to na automatiziranom testu koji ne mjeri kvalitativne razlike.
- Hrvatski jezik je differentiator - Modeli poput DeepSeeka i GLM-a koji su primarno trenirani na kineskom i engleskom imaju primjetne probleme s hrvatskom pravnom terminologijom. Qwen i Mistral su tu vidljivo bolji.
- Greške variraju po tipu zadatka - Nema modela koji je najbolji na svemu. Claude dominira na mobbingu, Qwen na najmu, Llama na radnom pravu. Zato je bitno testirati na raznolikim upitima, ne na jednom.
Zaključak
Qwen 3.5 397B je naš produkcijski model jer kombinira tri stvari koje su za pravni AI neprocjenjive: nikad ne izmišlja citata, piše besprijekoran hrvatski, i košta dovoljno malo da usage-based pricing ima smisla za male i srednje odvjetničke urede.
Benchmark ponavljamo svakih 2-4 tjedna s novim modelima i novim upitima. Svaki novi model koji izađe na tržište prolazi isti test prije nego što ga razmatramo za produkciju. Rezultate objavljujemo ovdje.
Za odvjetničke tvrtke kojima je EU data residency kritičan, Mistral Large je naša preporuka - drugi po kvaliteti, s garancijom obrade podataka unutar EU.
Kompletni benchmark podaci, uključujući pune odgovore svih modela na svih 5 upita, dostupni su na zahtjev. Pišite nam na info@lexbox.ai.
Zanima vas kako LexBox može pomoći vašem timu?
Isprobajte besplatno




